Haute Disponibilité avec Corosync et Pacemaker
La Haute Disponibilité désigne toutes les techniques permettant d'améliorer
la disponibilité d'un système ou de services et d'augmenter la tolérance aux pannes :
la redondance matérielle, les clusters, la réplications des données à chaud
physiquement (RAID 1 et RAID 5) ou logiciellement (Snapshots, DRBD), les scénarios
de crise (mode dégradés, plan de secours). Dans une grande entreprise, cela
peut donner lieu à un poste à responsabilité à plein temps. Mon activité professionnelle
m'a amené à mettre en oeuvre une facette de cette problématique : un cluster
actif / passif qui assure la disponibilité d'un service applicatif.
Pour GNU/Linux, j'ai expérimenté deux logiciels permettant de gérer une infrastructure de cluster :
- Heartbeat qui a fait ses preuves mais qui est limité : pas de cluster à plus de 2 noeuds, pas de gestion très fine des ressources et des règles pour basculer d'un noeud sur l'autre.
- Corosync et Pacemaker : c'est le choix de la distribution Red Hat et celui que je vais détailler dans la suite de cet article.
J'ai monté une maquette assez représentative composée de deux machines virtuelles Debian Wheezy (en version presque finale) avec 4 interfaces réseaux chacune qui font tourner un service Apache qu'on accède par une adresse IP gérée par le cluster.
Voici un diagramme réseau de la maquette :
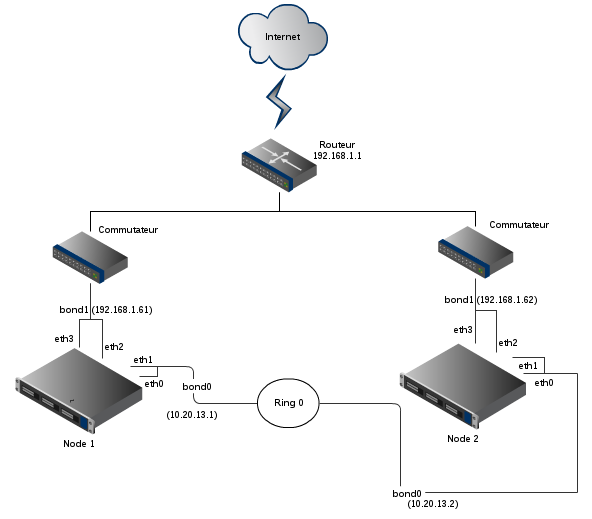
Les interfaces eth0 et eth1 font partie d'une agrégation logique de liens et servent au cluster pour vérifier l'état des autres noeuds. Elles constituent un réseau privé avec l'autre noeud dans le réseau 10.20.13.0/255.255.255.252. Les interfaces eth2 et eth3 font partie d'une autre agrégation logique, elles fournissent le service à l'extérieur dans le réseau 192.168.1.0/24.
L'agrégation logique (appelé aussi bonding) fournit une redondance supplémentaire. Si l'adaptateur réseau eth0 grille, le trafic transite encore grâce à eth1. On peut la configurer en mode actif/passif ou bien en mode load-balancing.
Voici la configuration des interfaces sur la machine vm-node1 dans /etc/network/interfaces/ :
auto bond0
iface bond0 inet static
address 10.20.13.1
netmask 255.255.255.252
bond_mode active-backup
bond_miimon 100
bond_downdelay 200
bond_updelay 200
slaves eth0 eth1
auto bond1
iface bond1 inet static
address 192.168.1.61
netmask 255.255.255.0
gateway 192.168.1.1
bond_mode active-backup
bond_miimon 100
bond_downdelay 200
bond_updelay 200
slaves eth2 eth3
et la configuration du bonding dans /etc/modprobe.d/bonding :
alias bond0 bonding
alias bond1 bonding
La configuration réseau de la machine vm-node2 est symétrique avec bond0 en 10.20.13.2 et bond1 en 192.168.1.62.
Quand la configuration réseau est ok, on peut s'occuper du cluster. D'abord il faut installer Corosync et Pacemaker, c'est trivial sous Debian :
apt-get install corosync pacemaker
Ensuite il faut configurer Corosync. Il gère l'infrastructure de cluster, c'est à dire l'état des noeuds et leur fonctionnement en groupe. Pour cela, on doit générer une clef d'authenfication qui sera partagée par tous les noeuds du cluster. L'utilitaire corosync-keygen permet de générer cette clef à partir d'entrées clavier pseudo-aléatoires qu'il faut ensuite sécuriser et copier sur les autres noeuds.
# génération de la clef depuis vm-node1
corosync-keygen
mv authkey /etc/corosync/authkey
chown root:root /etc/corosync/authkey
chmod 400 /etc/corosync/authkey
# copie de la clef sur vm-node2
scp /etc/corosync/authkey root@10.20.13.2:/etc/corosync/authkey
Corosync propose le concept d'anneaux de connexion pour assurer la communication entre noeuds. Dans le cadre de la maquette je définis deux anneaux : ring0, l'anneau de communication par défaut qui utilise le réseau privé et ring1 un anneau de secours qui transite par l'intermédiaire des commutateurs (ou switchs) avec le reste du trafic. C'est une sécurité de plus pour le cas improbable où les deux liens eth0 et eth1 soient cassés. Corosync permet de définir les anneaux en terme de réseau IP / masque réseau plutôt que de définir les adresses IP. C'est appréciable car le même fichier de configuration peut être déployé sur tous les noeuds sans rien changer.
totem {
version: 2
# How long before declaring a token lost (ms)
token: 3000
# How many token retransmits before forming a new configuration
token_retransmits_before_loss_const: 10
# How long to wait for join messages in the membership protocol (ms)
join: 60
# How long to wait for consensus to be achieved before starting
#a new round of membership configuration (ms)
consensus: 3600
# Turn off the virtual synchrony filter
vsftype: none
# Number of messages that may be sent by one processor on receipt of the token
max_messages: 20
# Limit generated nodeids to 31-bits (positive signed integers)
clear_node_high_bit: yes
# Disable encryption
secauth: off
# How many threads to use for encryption/decryption
threads: 0
# Optionally assign a fixed node id (integer)
# nodeid: 1234
# This specifies the mode of redundant ring, which may be none, active, or passive.
rrp_mode: passive
interface {
ringnumber: 0
bindnetaddr: 10.20.13.0
mcastaddr: 226.94.1.1
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 192.168.1.0
mcastaddr: 226.94.1.1
mcastport: 5407
}
}
amf {
mode: disabled
}
service {
# Load the Pacemaker Cluster Resource Manager
ver: 0
name: pacemaker
}
aisexec {
user: root
group: root
}
logging {
fileline: off
to_stderr: yes
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
tags: enter|leave|trace1|trace2|trace3|trace4|trace6
}
}
A ce stade, l'infrastructure de cluster est en place mais elle ne gère aucune ressource. Ca c'est le rôle de Pacemaker.
On impose les contraintes de fonctionnement suivantes :
- les ressources (le service Apache et l'adresse IP du cluster) tournent sur le serveur vm-node1 dans le cas normal.
- le service Apache et l'adresse IP du cluster doivent tourner sur le même serveur sinon notre service est injoignable.
- si le service Apache se crashe sur le serveur primaire, on bascule sur le serveur secondaire.
- si le serveur primaire ne joint plus la passerelle Internet, on bascule sur le serveur secondaire.
Pacemaker fournit quelques utilitaires en mode texte pour interagir.
- crm permet de gérer tout l'aspect configuration.
- crm_mon affiche l'état du cluster.
D'abord on définit la configuration globale. On désactive le STONITH (Shoot The Other Node In The Head) et le quorum. Le Stonith est la possibilité de tuer l'autre noeud s'il ne répond plus par l'infra de cluster. C'est faisable sur des vrais serveurs par IPMI par exemple. Quant au quorum, il n'a pas de sens sur un cluster à moins de 3 noeuds.
property stonith-enabled=false
property no-quorum-policy=ignore
On peut maintenant définir notre première ressource : l'adresse IP du cluster attaché au noeud actif.
primitive vip ocf:heartbeat:IPaddr2 params ip=192.168.1.60 cidr_netmask=24 nic="bond1" op monitor interval="10s"
Puis la ressource Apache, le service critique qu'on veut fournir dans cette maquette :
primitive httpd ocf:heartbeat:apache params configfile="/etc/apache2/apache2.conf" statusurl="http://localhost/server-status" op start timeout="60s" op stop timeout="60s" op monitor timeout="20s"
Le démarrage et l'arrêt d'Apache sont maintenant gérés par le cluster. Il faut fonc enlever le démarrage automatique du service. Sous Debian c'est avec update-rc.d :
update-rc.d -f remove apache2
Vous remarquerez qu'on va plus loin que la définition d'une ressource Apache. L'attribut statusurl permet à Pacemaker d'utiliser la page de statut d'Apache pour décider d'une bascule. Il ne faut donc pas oublier de configurer cette URL dans Apache pour que cela fonctionne :
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
Comme on a construit la configuration pas à pas, crm_mon remonte peut-être des erreurs sur certaines ressources car elle n'étaient pas opérationnelles. Il y a un compteur d'échec qui lève un message d'avertissement. on peut remettre ce compteur à zéro comme ceci pour la ressource http :
crm resource cleanup httpd
A ce stade on a une adresse de cluster et une ressource HTTP, mais pas forcément sur le même noeud. la ressource vip va basculer si le noeud tombe. La ressource httpd va basculer si le noeud tombe ou si le service apache tombe (surveillance par l'URL /server-status).
C'est sympa mais pas très utile :-) On va aller plus loin et forcer les deux ressources à tourner sur le même noeud C'est faisable grâce au concept de la colocation :
colocation httpd-with-vip inf: httpd vip
Et on voudrait que dans le cas normal, les ressources tournent sur vm-node1, notre noeud primaire :
location preferred-node vip 100: vm-node1
Enfin, on rajoute une condition de bascule. Si le noeud ne joint plus la passerelle Internet, on veut basculer les ressources sur l'autre noeud Pour cela on définit une ressource de type ping qui tourne sur tous les noeuds (grâce au concept de ressource clonée). Puis on rajoute une règle de location pour basculer si le noeud actif ne voit plus la passerelle.
primitive ping-gateway ocf:pacemaker:ping params host_list="192.168.1.1" multiplier="1000" op monitor interval="10s"
clone cloned-ping-gateway ping-gateway
location vip-needs-gateway vip rule -inf: not_defined pingd or pingd lte 0
Voilà notre maquette est opérationnelle.
Merci beaucoup! Très bonnes explications. Par contre je me permet de signaler une petite anomalie : Sur la ligne "primitive httpd ocf:heartbeat:apache params configfile="/etc/apache2/apache2.conf" statusurl="http://localhost/server-status" op start timeout="60s" op stop timeout="60s" op monitor timeout="20s" "
A la place du "monitor timeout" j'ai dû mettre "monitor interval". Sinon une erreur m'était retournée.
@seb Merci, j'ai en effet oublié de fixer une valeur pour interval. Peut-être que je l'avais fait de manière globale dans ma maquette
Une bonne intro claire et concise. good job!
je suis simplement impressionné
Merci pour ce schéma clair. Mon interrogation est la suivante pourquoi ne pas dédoubler les switchs dans votre configuration? Cela me semble augmenter la sécurité de l'ensemble.
@Norbert Bonne remarque ! L'article est surtout centré sur la redondance des serveurs et la mise en oeuvre système. Mais pour maximiser la disponibilité des services, la redondance doit aussi être être prise en compte au niveau du réseau et de l'alimentation électrique.
Clair et précis, merci pour cet excellent article;